
本问转载自公众号:极客果核
最近互联网上的一系列图片真的是活久见,打死我也没想到人类居然能整活到这种程度,先给大家伙放几张弔图开开眼。

没有看明白这些是什么的话,不妨摘下眼镜或者拿远点再看看。
对于这些图,我只能说《牛逼》。

你是否在疑问这是哪个摄影师整的活,也太diao了吧,这光影,这操作,真的是一般人能够做出来的吗,没错,这的确不是人做出来的,确切的说它们都是用AI 生成出来的。
类似的图还有很多,比如接下来这张《牛批》非常完美地将文字藏在了衣服和裙子的条纹中间,放大了图片基本上是看不出来的。

如果你觉得以上的图片和文字的融合还是比较生硬,那这张图的放大状态,绝对会让你再看好几眼都瞧不出来它是什么。

(图源@抖音 麦橘MAJIC)
如果你能在放大状态看清它,就只有两种可能性,要不就是你近视已经无药可救,要不你买的股票天天《涨停》,已经将这两个字刻进DNA了,化成灰都认识的程度!
那么这种惊艳的效果是如何实现的呢?这就再次搬出AI绘画工具的天花板之一“Stable Diffusion”啦,配合上ControlNet插件之后,AI绘画就能实现指哪儿打哪儿的效果。
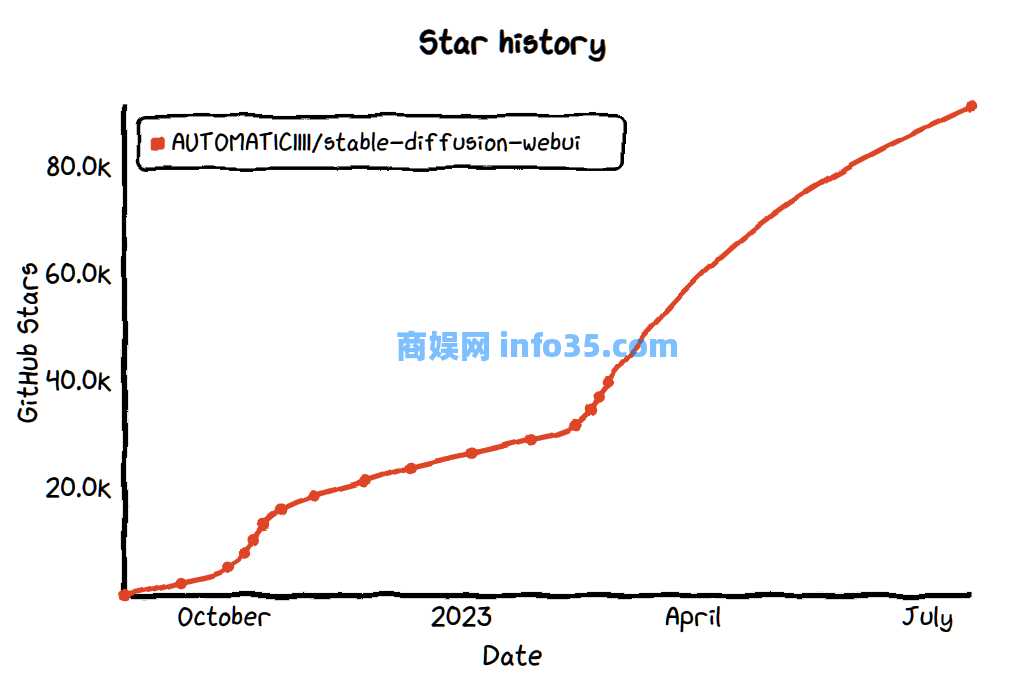
像是优化一下某处的细节或者对画面的某个地方甚至整体结构进行定制。如果将从前那些只凭着大方向自由发挥,它想画啥,我们把无法确定结果的AI绘图工具比作一位狂野的画家的话,那么现在搭配上ControlNet的Stable Diffusion就是一名听话的画师,让他改哪里他就得改哪里。
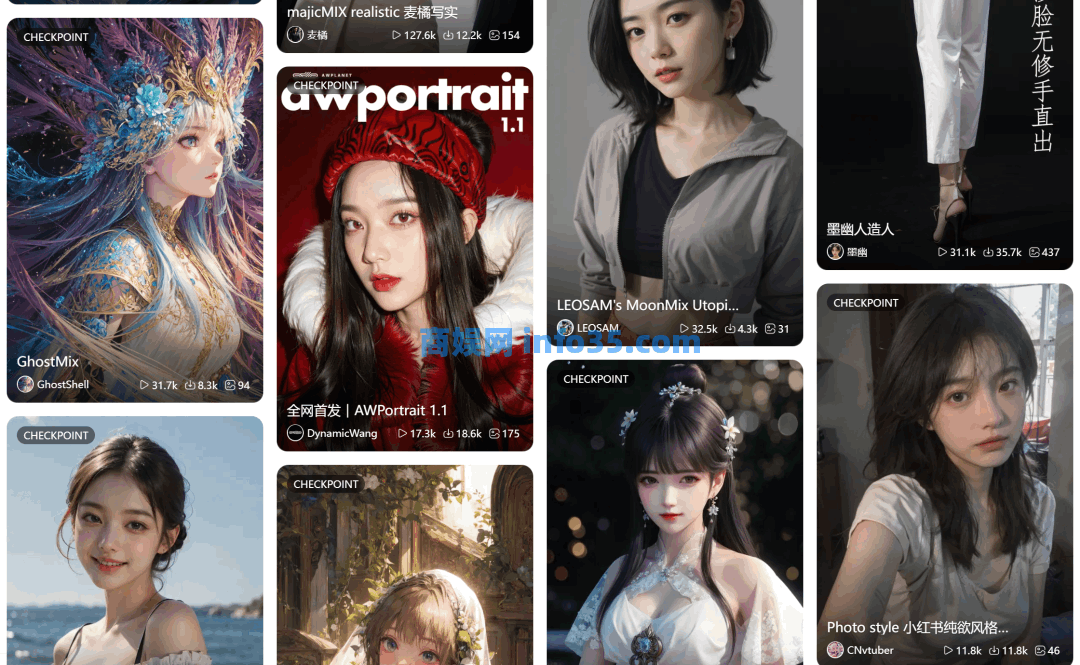
本来AI生成的图片大家已经见怪不怪,AI生成的人像内容,如果不仔细调整还是很容易看出来的,因为网上流传的图片模特的样貌大差不差,一般还都是人物主体加上略带虚化的背景,见多了会视觉疲劳和感觉厌烦,这次新出来的图片让大家在看图的时候,可以先大概观察藏了什么字,有了新奇和互动的感觉。
那么我们要如何使用软件才能最好地做出上面那种效果呢。
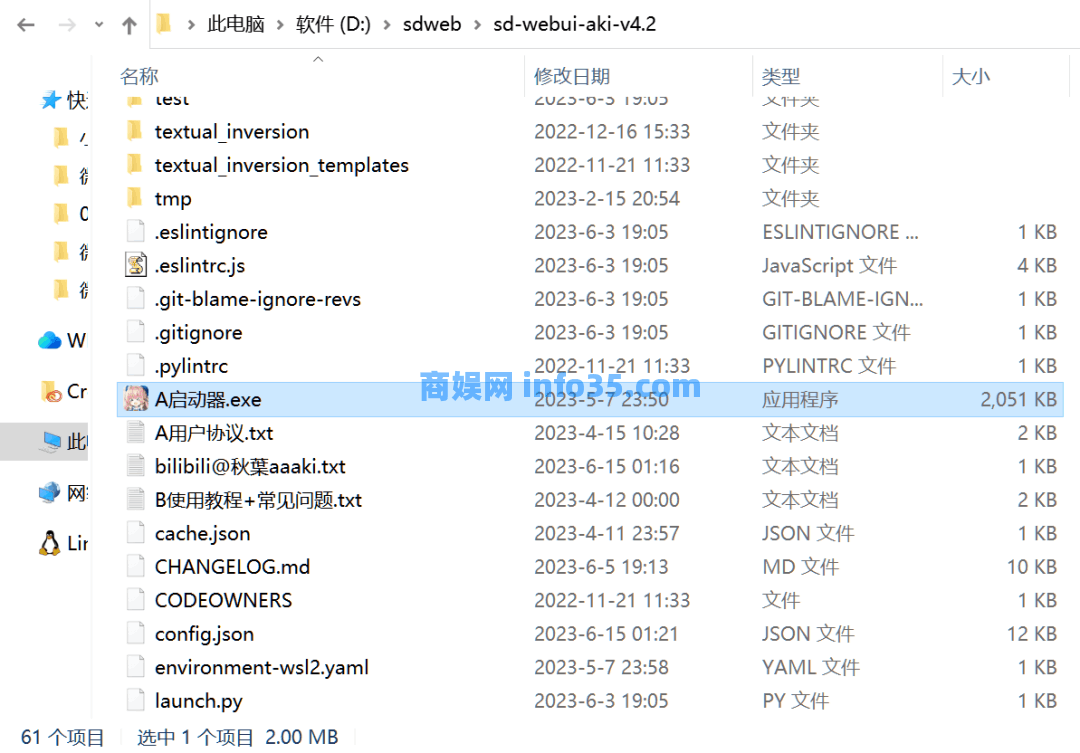
下载好启动器之后直接解压到你喜欢的地方去,值得注意的是你需要尽量保证硬盘的剩余空间大于50G,这东西解压出来其实还是不小的,接下来你需要先将ControlNet和模型配置好,打开启动器的版本管理,先点击扩展的一键更新。
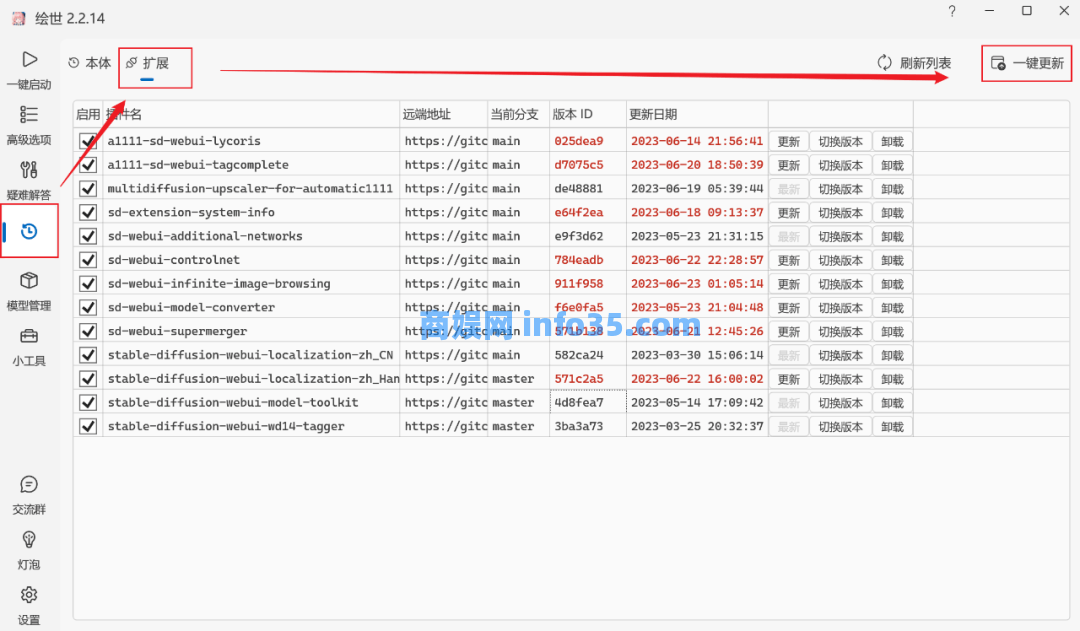
这里随便说一下相关文件的所在目录,下面这两步不是必要的,这里是为了告诉大家:只需要把文件移动到对应的位置,也就相当于完成“安装”的操作了。像是将@秋葉aaaki提供的文件夹controlnet下的“预处理器\downloads”文件夹放到启动器的“extensions\sd-webui-controlnet\annotator”下。
然后再将controlnet的“模型\”下的所有文件放到启动器的“models\ControlNet”下,就可以在后续的流程里面使用了。
但是要做上面的文字光影图片效果的话,需要使用效果相对更好的Brightness模型,需要放在“models\ControlNet”下,贴心的果核也一并给大家打包好了,如果刚接触看得有点云里雾里的也没有关系,在文末有打包好的环境,直接解压启动就好。
到这里为止,有了启动器的帮助,工具的安装部署过程其实就已经完成了。接下来我们点击“一键启动”就可以打开Stable Diffusion的WebUI化界面开始激情地创作啦。
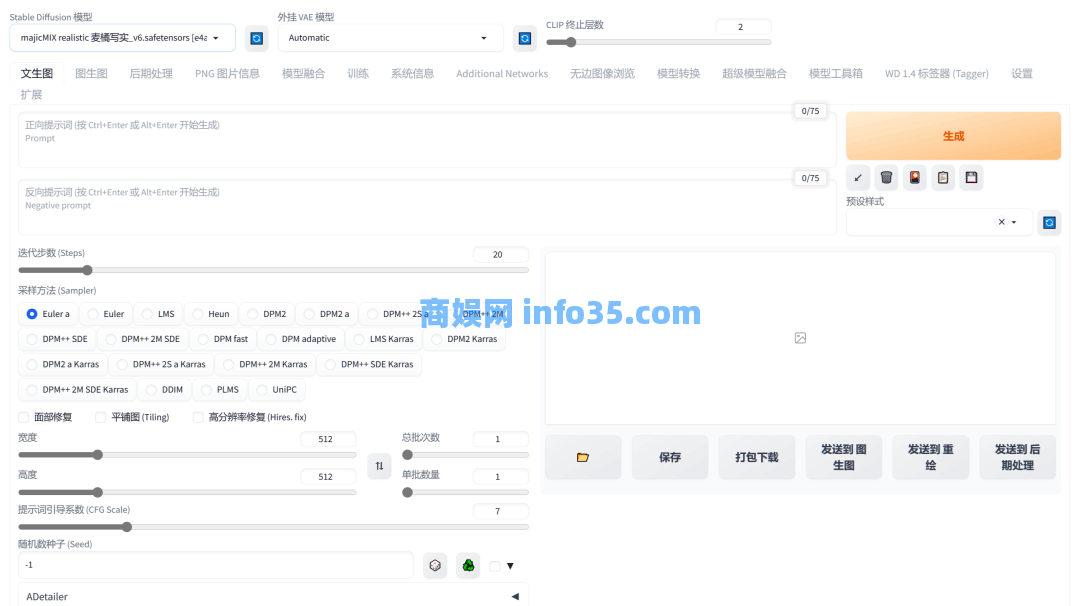
创作图像所需的步骤也不是特别复杂,大致就是选择Stable Diffusion 模型、填写正面和负面提示词、调整迭代步数和采样方法、调整ControlNet的参数、最后生成图片。
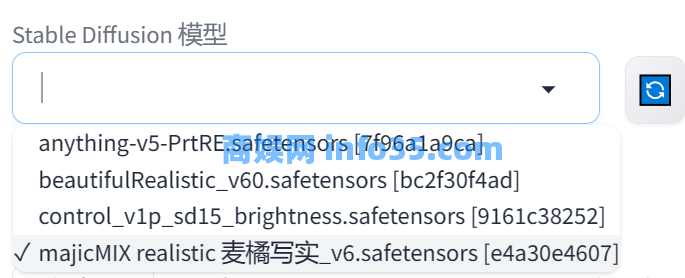
其中Stable Diffusion 的模型选项,主要就是切换不同的模型包,你可以理解为换一个画画的人,作用其实就是调整出图的风格,不同的模型之间生成的图片会有许多差异,大家可以去模型分享平台看看有没有自己喜欢的画风,挑选一个满意的下载安装即可。

这类绘画风格的模型,可以在启动器的模型管理界面,打开所在文件夹,将下载的文件移动进去,刷新一下就能使用了。
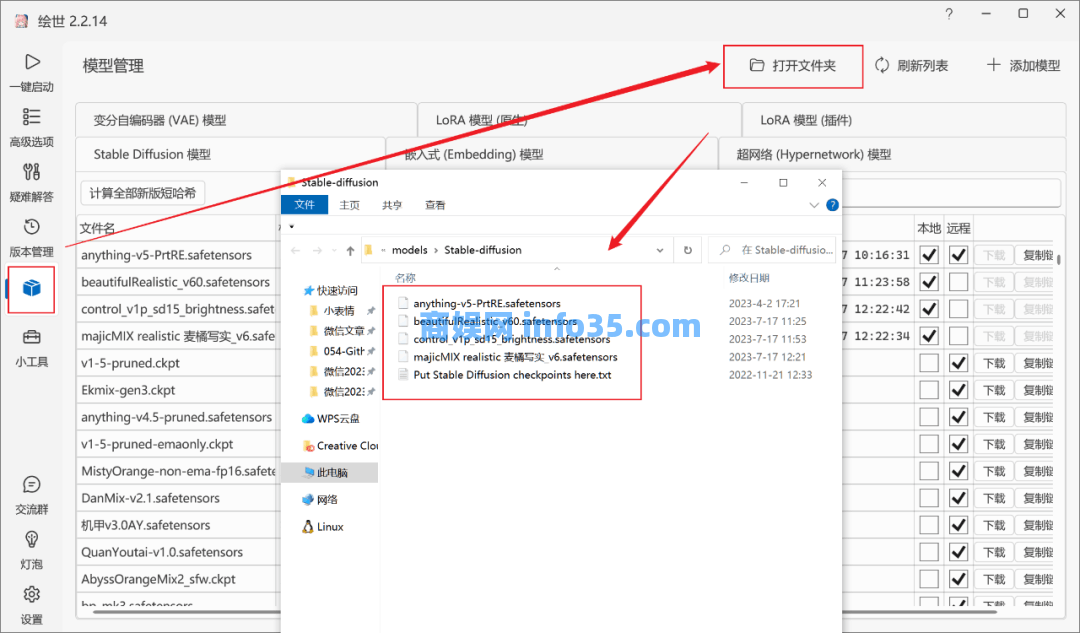
打包的文件里放了一个生成漂亮小姐姐的、一个动漫风格的,还有麦橘分享的一个写实风格的模型。
模型选择好了就可以进入发号施令的阶段了,此时我们需要提供给工具一些它易懂的话语,俗称“咒语”网上其实有许许多多的人发布自己尝试后觉得不错的“咒语”,在下载风格模型的时候,分享者一般会为了保持能输出差不多的图片,也会一段“咒语”,将这些提示词粘贴进去就好了,更多的,大家可以去找找然后慢慢尝试。
接下来是一些需要调整的。
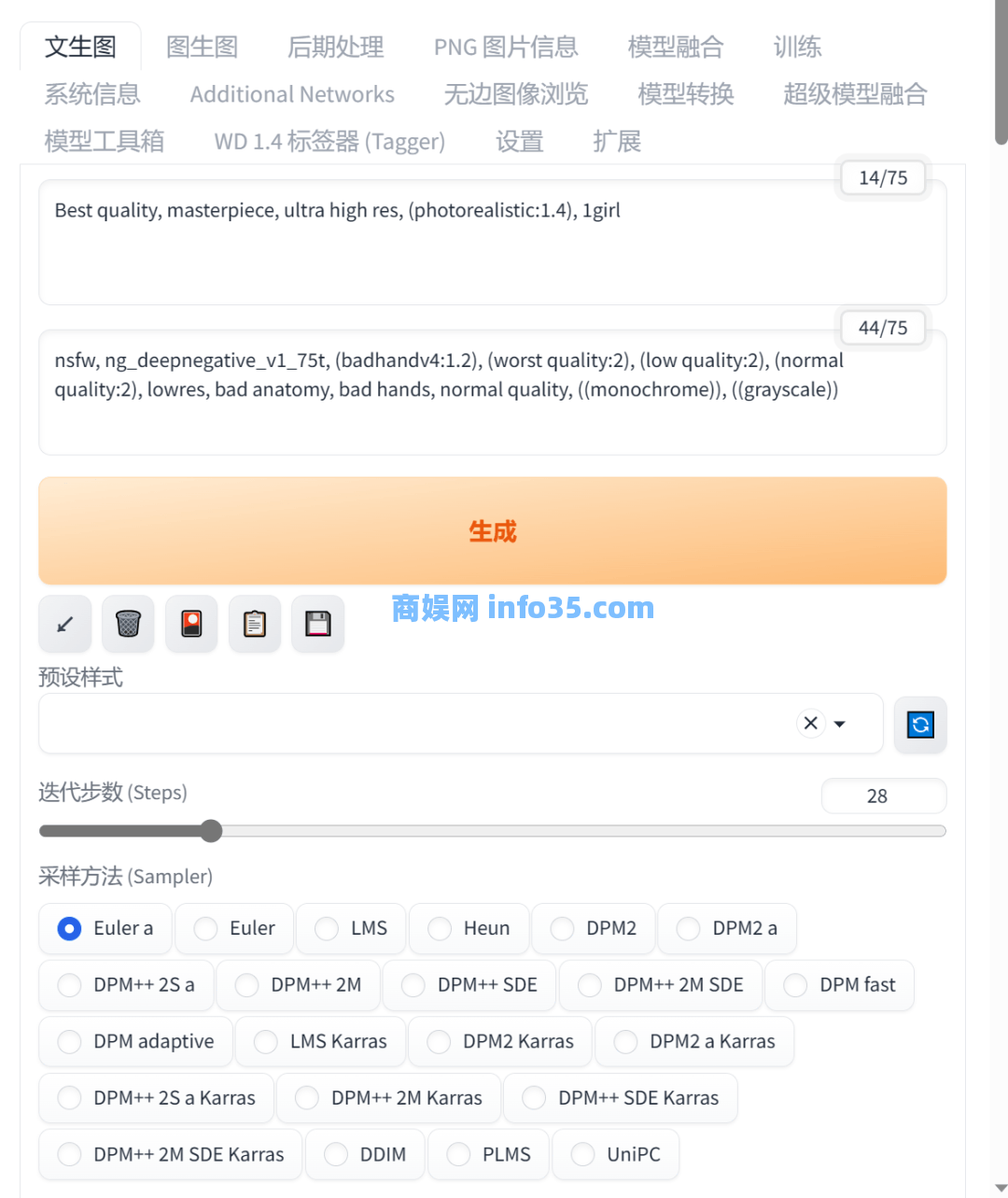
迭代步数:一般在25-30比较好,在下面的选项里还有一个“面部修复”按钮,这个按钮是看情况勾选的,如果你下载的风格模型本身输出的面部就很好了,再打开就会有一些比较奇怪的处理效果,这个在下载模型的时候,分享者一般都会告诉你要不要开启。

采样方法:这个制作光影文字可以尝试Euler a和Euler和DPM++SDE Karras(也可以根据网上总结的经验教程来),在这里选择好生成图片的宽高。
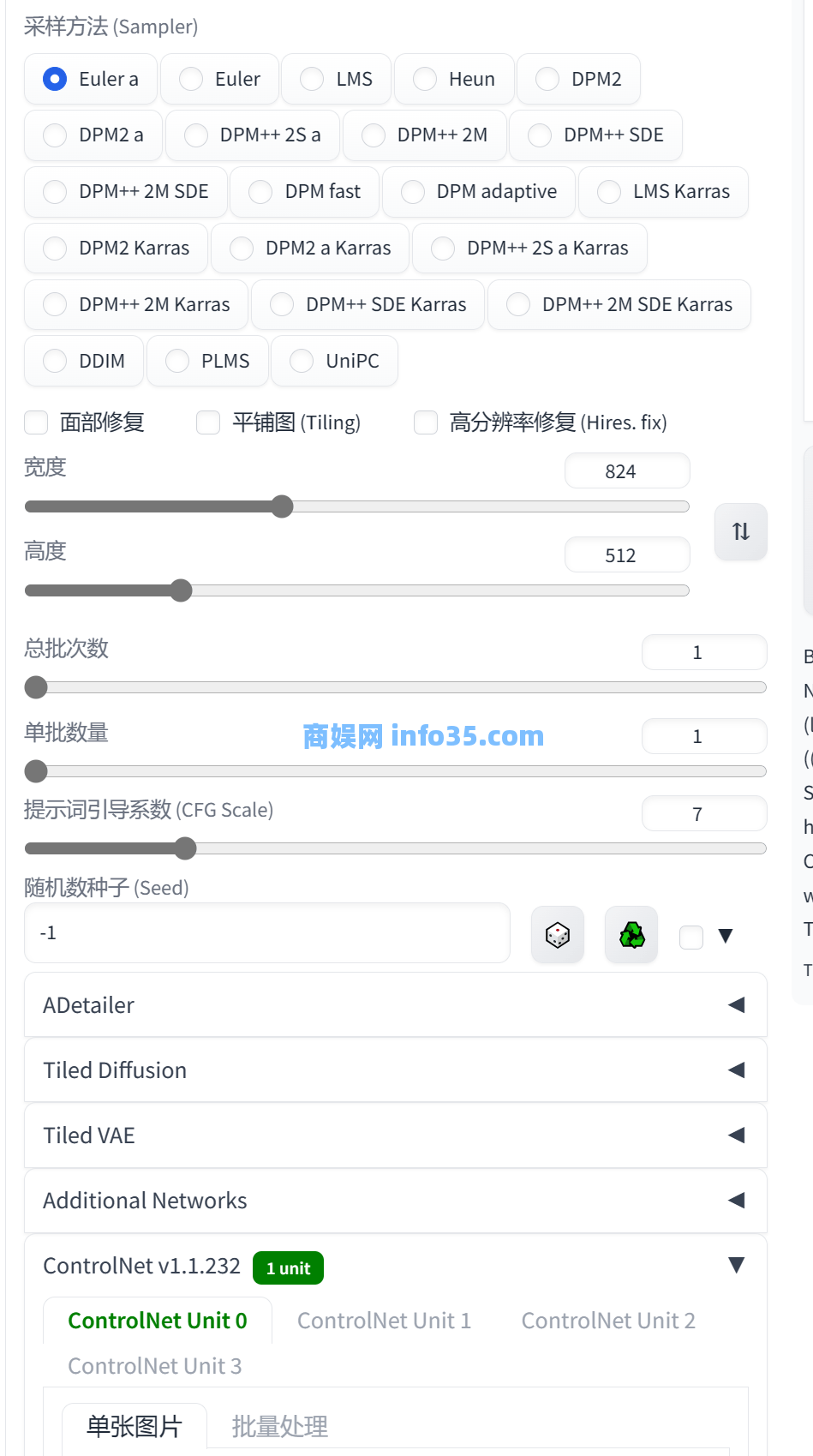
ControlNet参数(重要):
制作一张白字黑底的图片添加上去,在模型选项里面选择control_v1p_sd15_brightness这个模型。
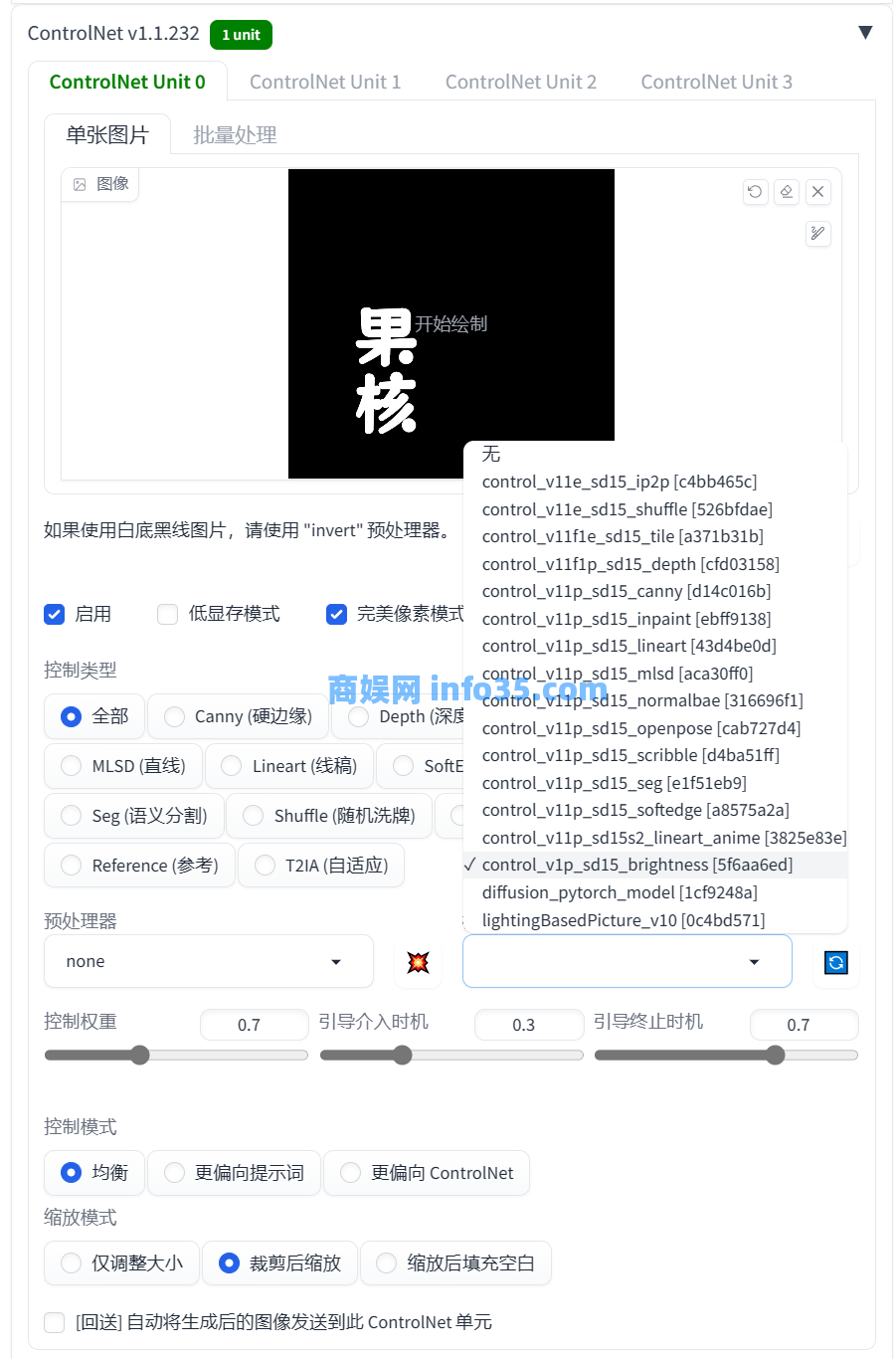
下面的参数,权重控制的参数大小会影响到文字的显眼程度,拉得越大就越显眼,太显眼的话也可以降低一点这个数值,低于0.4一般就不怎么明显了。



后面两个数值是引导控制文字介入的时间,它们的关系是:介入的影响远大于退出,越早影响越大,越晚影响越小。简单一点来说,介入的越早生成的图片就更像文字,介入的越晚,图片看起来就没啥变化。演示的介入时间是0,退出时间0.72。
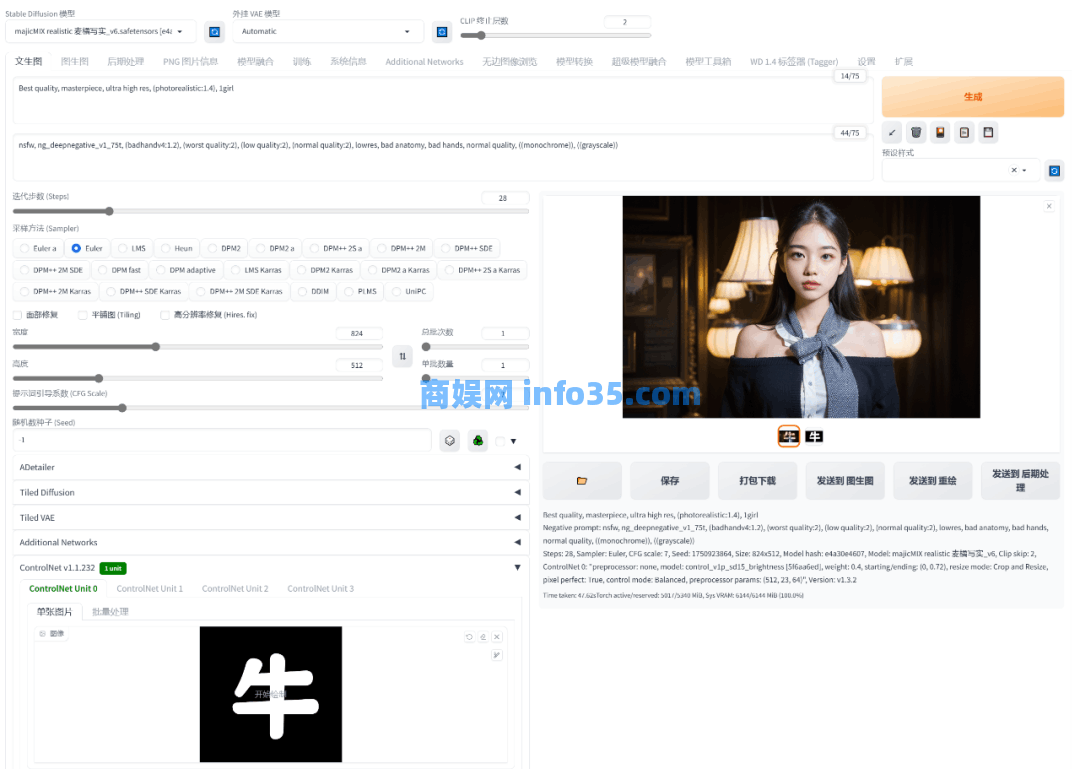

大致的流程就是这样,新手想要体验一下还是比较简单的,如果想要生成完美图片,就需要了解更多东西了,像是lora分层和after detailer修复工具,各种扩展等等,一套接一套的。
除了上面那种将文字/图形隐藏到画作中的操作之外,这几天还出来了一个将二维码极致美化的技术,就可以用上面的基础来融合一些其他的东西了,下载一些适合的风格模型,一般是风景和动漫类的,单纯人物的话不好控制。
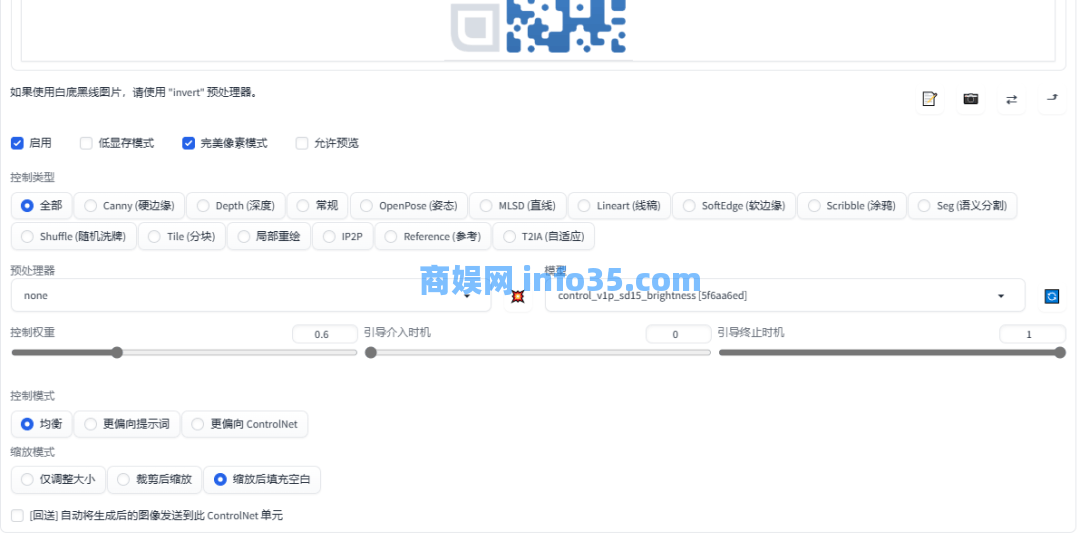
将替换的文字图片换成二维码原图,然后换些提示词来生成需要的效果。
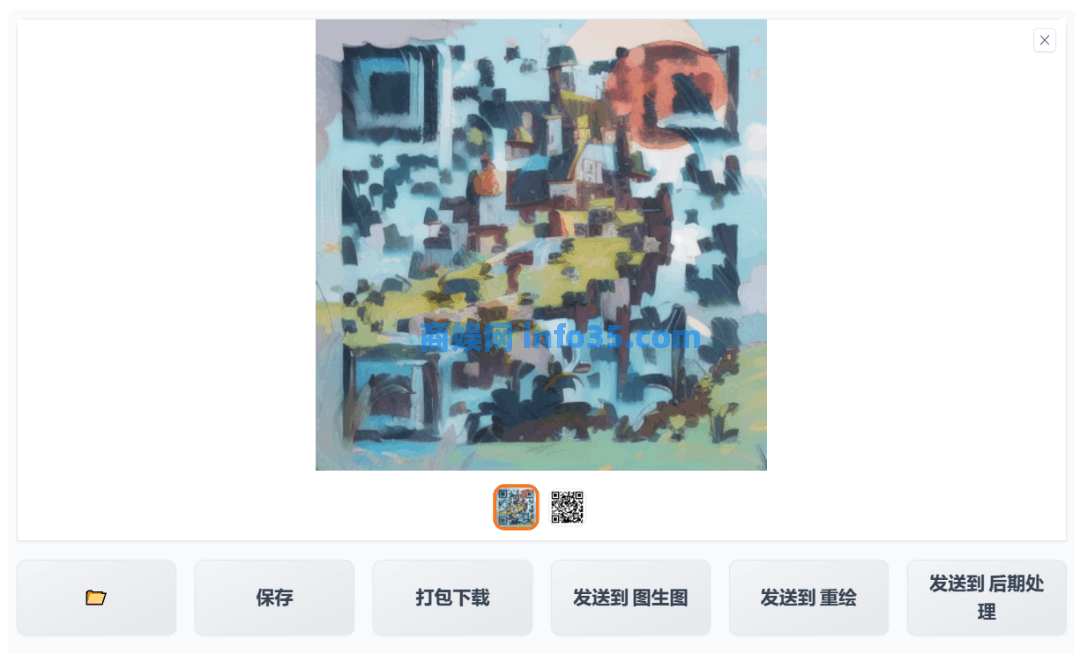
AI的生成的效果可以随二维码原本的风格变化,可以先使用工具先对二维码进行处理,改变二维码的点阵与定位点样式,有些时候不是二维码看起来越简洁,生成的效果就越好,让二维码凌乱一点,说不定AI发挥的空间越大。
如果只是为了美化二维码,主要是能让二维码能快速扫出来,那么更开始尝试的时候,可以将控制权重调大一些,介入和退出时间设置成0和1,尝试一下成功后,再使用其他的参数。更多细节处理的办法,果核把详细教程放在了知识星球,大家可以在文末的拓展阅读里加入查看。
有了这些工具,就不需要在网上找付费的工具了,自己捣鼓一下,可自定义的程度和细节更高,比已经搭建好的服务更自由,说不定能找到你自己的专属风格。
夸克网盘下载链接:https://pan.quark.cn/s/a5d5bcb3b35a
© 版权声明
商娱网所有文章,如无特殊说明或标注,均来自于互联网或为商娱网用户原创发布。任何个人或组织,在未征得原作者同意时,禁止复制、盗用、采集、发布商娱网内容到任何网站、书籍等各类媒体平台。如若商娱网内容侵犯了原著者的合法权益,可联系我们进行处理。
相关文章



暂无评论...







![2026年最新收集可用、好用、稳定值得推荐的磁力搜索引擎[更新版]](https://img.info35.com/info35/2026/01/1768129104-gfyvtyqet1rmr0cvnjs968tj54.png)

